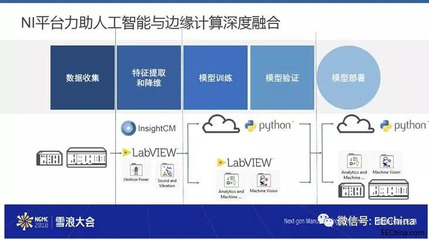
大數據時代下的精準商業情報采集 以阿里巴巴1688電商網站為例
在當今數字化浪潮席卷全球的背景下,大數據已成為驅動商業決策與創新的核心引擎。其中,電商數據和互聯網數據采集,作為獲取市場動態、競品情報及消費者洞察的關鍵手段,其戰略價值日益凸顯。本文將聚焦于阿里巴巴1688這一全球領先的B2B電商平臺,探討其貨源產品信息采集的實踐路徑、技術挑戰與應用前景,以揭示大數據信息資料采集在現代商業生態中的核心作用。
一、阿里巴巴1688:海量貨源產品信息的富礦
阿里巴巴1688平臺匯聚了海量制造商、批發商與供應商,覆蓋從原材料、工業品到消費品的全品類商品。其平臺上每日更新的產品信息——包括商品詳情、規格參數、價格波動、供應商資質、交易評價、庫存動態等——構成了一個實時、多維的商業數據庫。系統性地采集這些信息,能夠為企業提供以下關鍵價值:
- 供應鏈優化:通過分析不同供應商的產品質量、價格區間、交貨能力及信譽評價,采購方可實現供應商的精準篩選與動態管理,降低采購成本與風險。
- 市場趨勢洞察:追蹤熱銷品類、新興產品、價格走勢及區域分布,幫助企業把握市場先機,指導產品開發與生產計劃。
- 競品分析:監控競爭對手的產品策略、定價模型、營銷活動及客戶反饋,為自身市場競爭策略的制定提供數據支撐。
二、電商數據采集的技術實現與核心挑戰
對1688這類大型電商平臺進行高效、合規的數據采集,通常需要結合多種技術手段與策略。
1. 主要采集技術
網絡爬蟲(Web Crawling):這是自動化采集的基礎。通過模擬瀏覽器行為(需處理JavaScript動態加載),定向抓取目標商品列表頁與詳情頁的HTML數據。
API接口調用:若平臺提供官方或授權的數據接口,通過API獲取結構化數據是更高效、穩定的方式,但通常有權限和頻率限制。
* 數據清洗與結構化:采集的原始數據(文本、圖片、視頻等)需經過清洗、去重、解析,并轉化為標準化的結構化數據(如JSON、CSV格式),以便于后續存儲與分析。
2. 面臨的核心挑戰
反爬蟲機制:平臺為防止數據被濫用,部署了IP限制、請求頻率驗證、行為識別(如鼠標軌跡)等多重反爬措施。這要求采集方案必須具備IP代理池、請求隨機延時、模擬人類操作等應對策略。
數據動態性與規模:平臺數據更新頻繁,商品上下架、價格調整瞬息萬變。要實現數據的“保鮮”,需要設計合理的更新頻率與增量采集機制。海量數據的存儲與處理對硬件與架構提出高要求。
* 法律與合規邊界:數據采集必須嚴格遵守《網絡安全法》、《數據安全法》及平臺自身的Robots協議。采集行為不應干擾目標網站的正常運行,所獲數據應用于合法合規的商業分析,避免侵犯商業秘密與個人隱私。
三、從數據采集到商業智能:應用場景深化
采集到的原始數據經過深度分析與挖掘,才能轉化為驅動增長的商業智能。
- 價格智能與動態定價:通過實時監控全網同類商品價格,結合成本、供需關系,為企業制定具備競爭力的彈性定價策略。
- 產品創新與選品決策:分析品類增長趨勢、用戶評價關鍵詞、外觀設計流行元素,指導新產品研發與跨境電商業者的選品決策。
- 風險預警與信用評估:監測供應商的經營穩定性(如商品數量變化、投訴率)、行業政策動向,構建供應商信用模型,提前預警供應鏈風險。
- 市場進入策略研究:綜合分析不同區域、不同細分市場的商品豐富度、競爭烈度、價格水平,為新市場開拓提供量化依據。
四、未來展望:智能化、合規化與生態化
隨著人工智能與云計算技術的發展,電商數據采集正朝著更智能、更集成、更合規的方向演進:
- AI增強采集:利用自然語言處理(NLP)理解商品描述與評論情感,計算機視覺(CV)識別商品圖片中的關鍵信息,提升非結構化數據的處理深度。
- 云原生與實時處理:基于云平臺的數據采集與處理流水線,能夠實現資源的彈性伸縮,并支持流式計算,滿足對數據實時性的極高要求。
- 合規數據生態:平臺方、數據服務商與使用方之間,有望通過建立更規范的數據合作與交易機制,在保障數據安全與隱私的前提下,促進數據要素的價值合法流通。
###
對阿里巴巴1688等電商平臺的貨源產品信息進行系統化采集與分析,已成為現代企業供應鏈管理、市場研究與戰略決策的必備能力。這不僅是一項技術工程,更是一項融合了商業洞察、法律遵從與倫理考量的戰略實踐。在數據驅動的掌握高效、合規、智能的數據采集與應用能力,將是企業構建核心競爭優勢、決勝數字經濟時代的關鍵所在。
如若轉載,請注明出處:http://m.pcfjmedemocratic.xyz/product/24.html
更新時間:2026-06-19 21:18:47